Can an orderbook be a public good?

The Derive Matcher is going open-source!
There is much duplicate work being done on orderbooks in crypto, and much more to be done still, as the crypto techstack rapidly evolves. We felt it would only benefit the DeFi ecosystem, and ultimately our users, to open up the first all-in-one self-custodial orderbook.
Orderbooks have existed in crypto for years, but with speed and better UX came centralization. That changes now. With the Derive Matcher users retain control of their funds and the security of on-chain liquidations, while enjoying the throughput and feature-set of CEX alternatives.
Features you get out-of-the-box:
- High-throughput REST / WS APIs for account management, streaming market data, and advanced orders
- Matching and risk engines
- Market-maker protections
- Settlement and event-listening on EVM chain
- Advanced authentication and rate limits
- Deploy cluster to any cloud-provider via Kubernetes
Why can’t it all be on-chain?
A feature-complete, high throughput orderbook is a significant amount of work, so it’s worth briefly going over one of the technical reasons for why we built one at Derive.
Similar to Optimism, the past two years at Derive was a journey from monolithic to modular. The V1 AMM was the smart contract equivalent of a mullet - a sleek, industry leading options venue in the front with maybe a bit too much stuffed in the backend. All four stages of an options trade (clearing, risk, matching and pricing) were packed into a single smart-contract AMM.
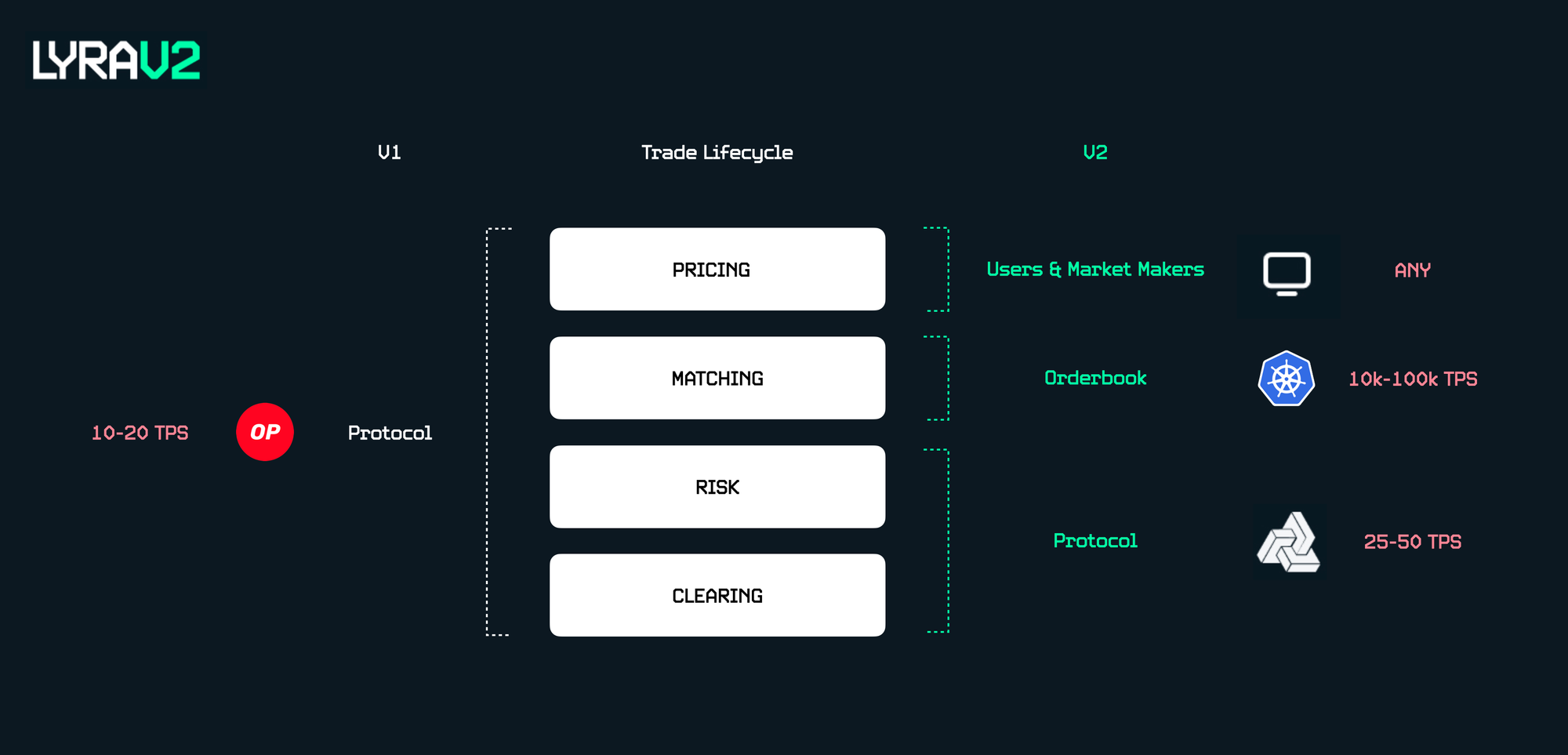
Despite pushing on-chain options to the next level, we began to (a) run out of gas and (b) experience slowing development speed with every release. How did this happen?
- Pricing: the V1 AMM performed gas-heavy computations to algorithmically determine price as a solution to the high cost of posting limit orders on-chain (similar to Uniswap).
- Matching: as a knock-on effect, the AMM became the counterparty to every trade. In addition to computing price, the AMM had to hedge itself on-chain against SNX / GMX - more gas used.
- Risk & Clearing: every trade still required a risk check and balance adjustment
Our ambitions for V2 were two pronged; settle >10x volume and offer advanced portfolio margin. Both require more block space. Our approach needed to change.
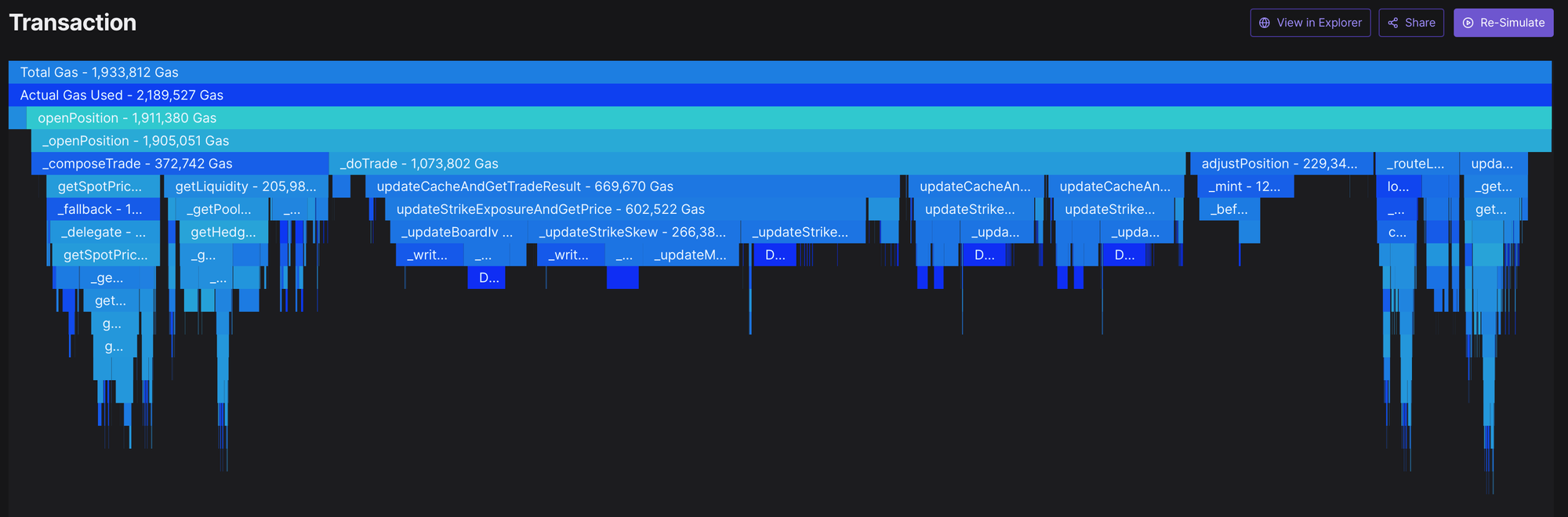
Finding a way to trustlessly move A-C off-chain would save us 70% of block space!
A. ~1mln gas: recalculating the price of the AMM surface [”Pricing”]
B. ~200k gas: AMM hedging risk via GMX [”Matching”]
C. ~100k gas: AMM safety features [”Matching”]
D. ~200k gas: AMM and trader margin checks [”Risk”]
E. ~350k gas: saving new balance values [”Clearing”]
In V2, all four stages were split out, with “Pricing & Matching” going off-chain. We got more block space for more volumes and advanced portfolio margin, the team could parallelize the work, and self-custody / on-chain risk was retained.
A public good
We could not find any open-source orderbooks that could be forked and run at scale. Of the few repos, most are just matching engines. To make an ETH parallel, it’s similar to releasing an ETH execution client but leaving out validator clients, RPC nodes, archive nodes, a JSON-RPC spec, block explorers, indexers and etc.
No CEX has opened up their work, and probably for good reason. In a custodial orderbook, a security event means market manipulation and maybe even complete loss of customer funds. The more “black box” you keep it, the safer.
This is no longer the case thanks to self-custodial orderbooks! Security is contained within the smart contracts. In the case of a hack on the orderbook:
- Customer funds simply cannot be touched as the orderbook never had access to them to begin with
- Outstanding orders can’t be manipulated as each order has a limit price signed by user private keys
- Trading is not blocked as each user can withdraw their account (assets and cash) directly on-chain and find counterparties on-chain
- All counterparty margin and risk remains collateralized as liquidations are fully on-chain
Beyond security, we deliberately chose a Kubernetes-based architecture so that any fork can choose their own cloud provider. AWS, Azure, GCP all have great Kubernetes hosting services. You can even launch your own tiny booklet from your orderbook!
Lastly, the Derive Protocol contracts are completely un-opinionated to what pricing and matching stack you use - whether it’s an AMM or an off-chain orderbook. There is no DAO “designated” matcher, as multiple orderbook forks can settle to the Derive clearing, liquidations, oracle smart-contracts at the same time.
Though it was painful to “reinvent the wheel”, and we still have much to learn, we hope others can benefit from and contribute to our initial work in self-custodial orderbooks.
Reinventing a very complex wheel
If you think about building an orderbook as a personal project, the first thing you probably think about is crafting the most efficient matching engine. Ironically, the core of the orderbook is the least time consuming. As with most things, the dozens of critical little micro-services is what takes a giant amount of work.
DEXs don’t have this issue as the hard work is handed off to existing ETH infrastructure:
- Risk checks / balance updates are computed by ETH Execution Nodes
- Latest market data can be scraped from Dune, GraphQL, RPC Nodes (e.g. Infura)
- Asset / account notifications can be subscribed to via RPC Nodes
- APIs don’t need to be hosted as
publicfunctions in Solidity are directly callable - No need for Postgres / MongoDB / etc as data availability is guaranteed by ETH Validator Nodes
- Rate limiting is automatically handled via EIP1559
No wonder we’ve seen hundreds of DeFi protocols deployed in a span of several years!
An orderbook must build much of the above from scratch AND handle 1000x more throughput. For us, the first step was to absorb as much as we can from the best CEX architectures:
- JaneStreet: What is an exchange
- Coinbase: Rearchitecting Apps For Scale
- Coinbase: Container Technologies at Coinbase
- Coinbase: Scaling Container Technologies with Kubernetes
- Robinhood: How We Scaled Robinhood’s Brokerage System for Greater Reliability
- Robinhood: Part I Scaling Robinhood Clearing Accounting
- Gemini: Develops Transformation Building A Culture of Full Automation
- Kraken: Performance at Kraken
- Kraken: Improving Kraken Infrastructure using Rust
And some great tech companies:
The design
The four things we prioritized:
- Scale horizontally
- Keep it simple
- Just use Kubernetes
- “Why can’t it run on my laptop?” (or if it passes on my laptop it will pass in prod)
1: Scale horizontally
It’s tempting to deploy the whole thing in one gigantic machine, all written in C++ or Rust - fully synchronous and blazing fast, maybe sprinkle in some custom hardware. But think about a high pressure situation, your user base doubles one day and your server is crashing. It’s midnight, you’re not exactly sure what’s making it sluggish, but you think you can gain some speed by caching certain variables in your risk checker. You buckle in to start implementing the improvement, traders are complaining all over twitter, and every minute you spend refactoring / testing your code is a minute that your users can’t trade. We want to avoid these nightmares.
The solution is a system where you can “throw CPUs” at as many problems as possible, giving you time to calmly work on business logic optimizations in parallel.
In our distributed system, we split out our APIs, Queues, DBs and Microservices into many standalone workers. If another 10,000 users flood our WebSocket servers, we just add 50 more pods. If our RabbitMQ queue is struggling to cope with the order flow, we increase CPU limit for that pod. If our risk checkers are struggling to keep up with surging order flow, we add another 50 pods. Kubernetes makes it even easier to respond to such events by scaling CPUs, RAM, or number of pods with a one-liner .yaml change.
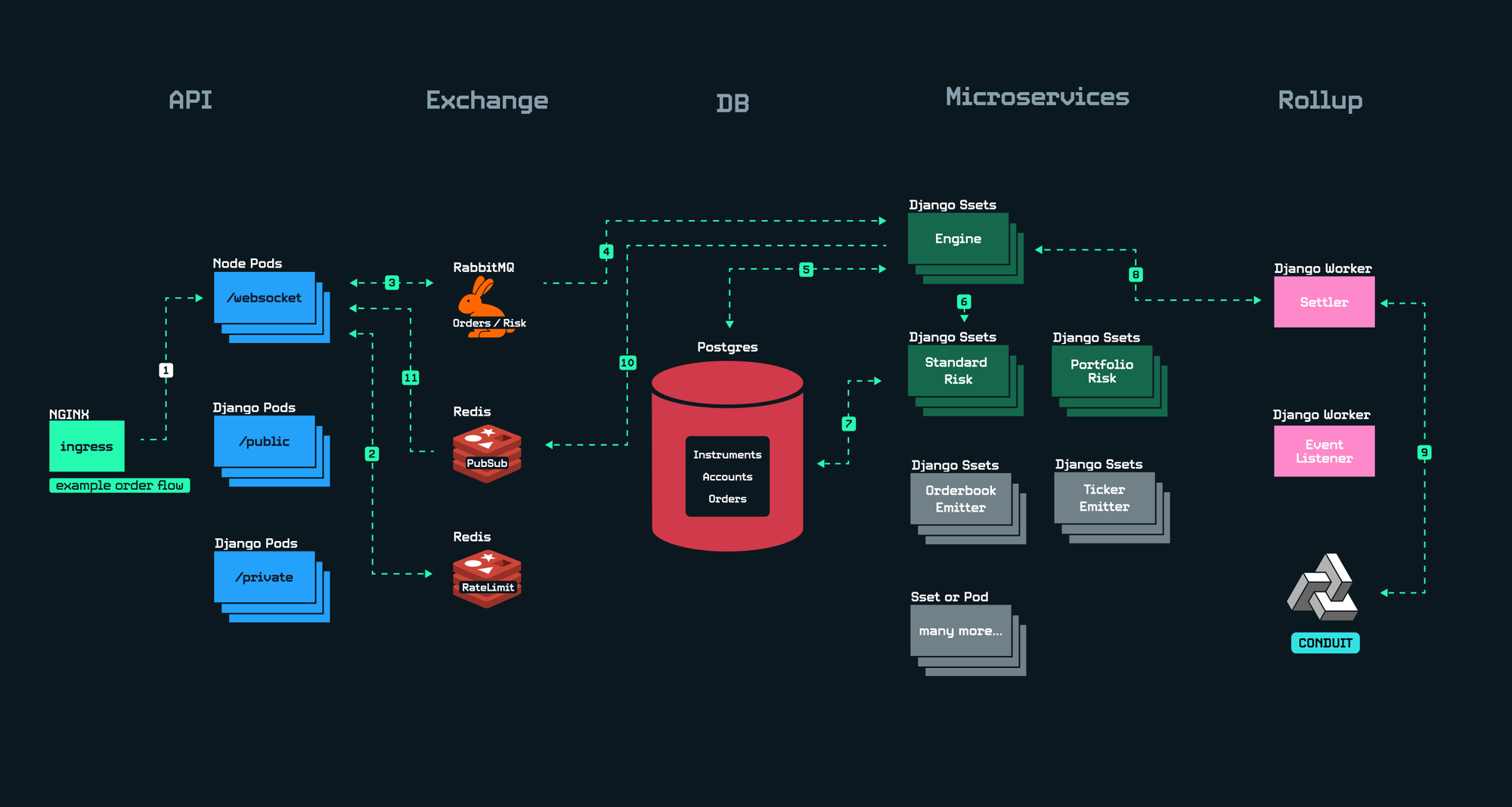
An additional benefit of horizontally scaling is modularization. When each service runs on a separate worker and communicates with other services in a predictable manner, the language / framework is swappable. Converting our WebSocket server from Node.js to Rust can be done with zero downtime and no changes to any other services.
2: Keep it simple
There are some processes that must be strictly atomic - e.g. the matching engine. You cannot simply have 10 separate engines settling trades for the same instrument - how would you know which open order is filled and which isn't?
Horizontally scaling this component took more thought. An engine has many tasks, and we slowly resected anything parallelize-able:
- Must serve ~500 instrument types per currency - parallelize our engines to service one instrument each. Adding 500 more strikes of FileCoin would not require re-architecting the whole system.
- Check margin of each counterparty - create pool of risk pods that can be scaled independently of engines. So a trade with 1 vs 10 counterparties is near constant time.
- Query / modify / edit orders and balances in DB - see below
- Publish tx on-chain and verify settlement - on-chain settlement to the Conduit-powered rollup is handled asynchronously via a separate worker. In the case of intermittent RPC Node failures, the engine would move on to the next order and let the settler handle reversions.
- Publish results to all subscribers (e.g. owners waiting for confirmation, users listening to trade events, etc) - leverage Redis and RMQ to broadcast events
And still… there was one final bottleneck, the Postgres Database. At the limit (imagine 10,000 live instruments all running on performant Rust engines), Postgres must handle balance and order updates serially for each parallelized pod (engines, risk workers, etc).
So do you take a 2 month long pilgrimage down Postgres sharding, or shove it under the rug? Robinhood has a great blog describing their long term solution.
💡 It was time to take a step back. Our goal was not to land an orderbook on Mars, but to exceed CEX throughput by some margin. We set tangible metrics → Product-Market-Fit * SomeSafetyMultiple (leaving out specific metrics for brevity). From the same Robinhood blog, we learned that their brokerage system used a single giant Postgres instance up until June 2020, serving 750k req/sec! 2020 Robinhood definitely sounds like a good enough ceiling for PMF. Almost too much PMF 😆.
Clear product requirements kept our architecture as simple as possible. The huge added benefit is the reduction in cost to maintain the system.
3: Just use Kubernetes
When beginning work on a large distributed system, it’s tough to embrace a seemingly complex framework like Kubernetes, especially when cloud providers are trying to convince you to use their easy-to-use / auto-managed / lock-in services.
In the past 5 years, most of the best tech companies have migrated their services onto Kubernetes. In addition to greatly simplifying infrastructure management, the open source software has been flexible enough to onboard their legacy systems and even allow them to build tools on top of it. Here is a brief primer on Kubernetes and why you should use it (from Stripe), or another one with a pointed example (from Shopify).
For a small team like ours, beyond the advanced features, an open-source framework with a huge developer community that is still growing was key. Using relatively niche cloud-provider services meant relying on how quickly they respond to your slack messages. DeFi never sleeps, what happens when your cluster starts throwing errors 3am cloud provider time?
Search any k8s question on StackOverflow, ask ChatGPT to create a ConfigMap using Bitnami Secrets, or ask a devops friend about k8s liveliness checks and you’ll see how large the community is.
4: “Why can't it run on my laptop?”

Step one is to get tests that you trust before you make changes to the codebase.
<…>
So Twitter had some stuff that looked kind of like this, but it wasn't offline, it was only online. <…>
So you can't run all of Twitter offline to test something. Well then this was another problem. You can't run all of Twitter. Period. No, this is bullshit. Why can't it run on my laptop?
We’ve got much to learn from George, but we took this tidbit especially to heart. From the first few commits, we realized abstracting away Kubernetes complexity from the rest of our team was crucial to our cadence.
Provisioning compute resources / networking / security / version roll-out on multiple clusters is a full time job. Requiring each dev to understand this slows down their day-to-day productivity.
This is why we leveraged Docker-Compose so you can run our fully featured Derive orderbook (including a Foundry Anvil blockchain) on your laptop! All of our end-to-end integration tests can run locally, giving our devs the critical confidence that - “if it passes on my laptop it will pass in the cluster” with ZERO knowledge of how Kubernetes works.
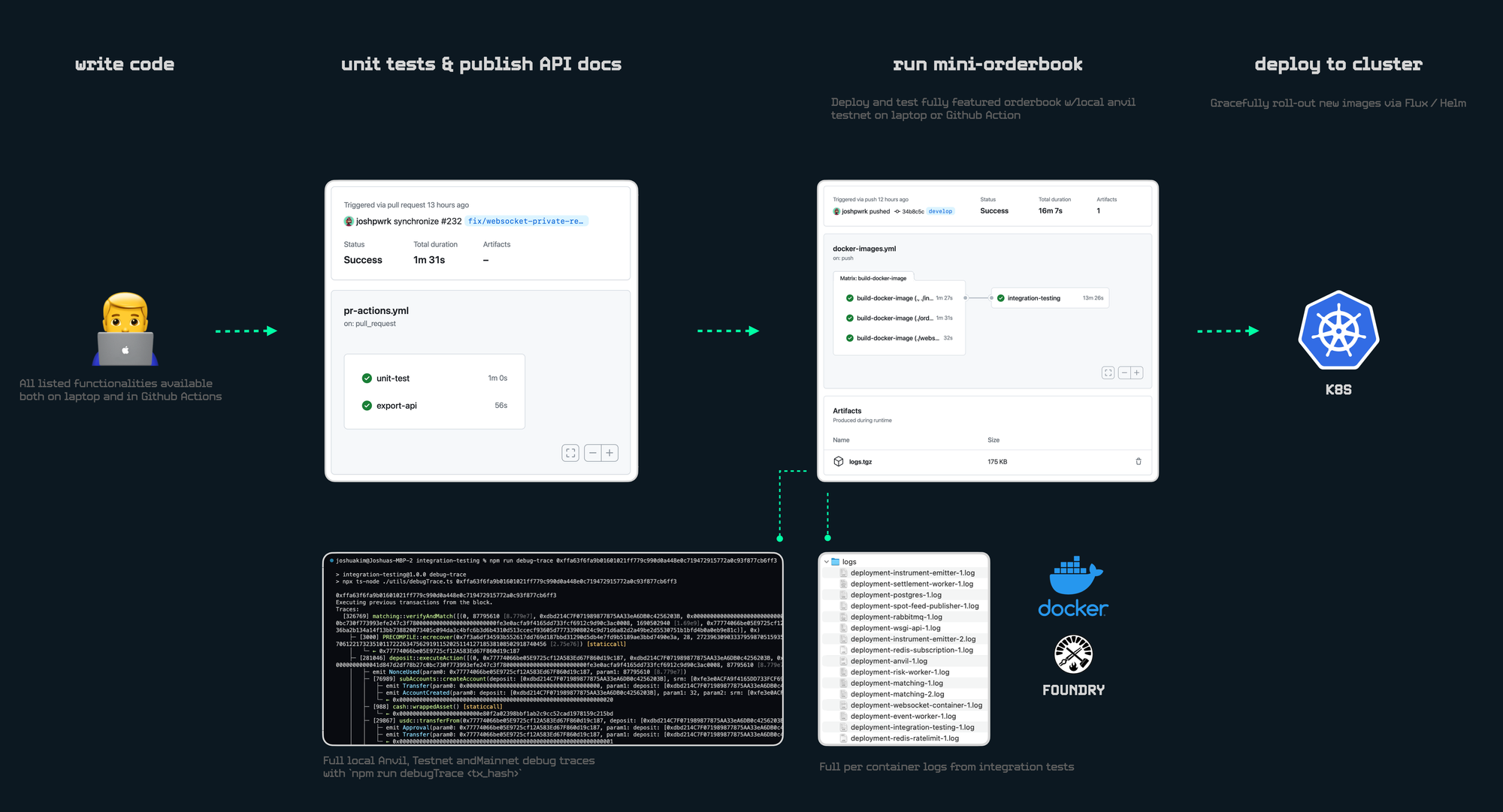
Having an end-to-end stack on a laptop means our CICD benefits too. Each PR cicd pipeline:
- Unit-tests
- Exports API docs
- Builds all new Docker images
- Spins up a mini orderbook cluster (using Docker-Compose)
- Runs end-to-end integration tests inside a Github Action
- Settles all transactions to a local Foundry Anvil blockchain
- Has downloadable debug logs for all workers in the orderbook
- Complete on-demand ETH transaction debug trace (using Foundry Cast) for local, testnet and mainnet transactions
The repos will go public shortly after the public Derive launch. This is just an initial work on a quickly evolving product, but we hope it’s useful to all the DeFi devs!If you’re interested, sign up for Derive.
Derive is the infrastructure layer for DeFi derivatives, visit derive.xyz.